As part of my involvement with the Nikita Noark 5 core project, I have been proposing improvements to the API specification created by The National Archives of Norway and helped migrating the text from a version control system unfriendly binary format (docx) to Markdown in git. Combined with the migration to a public git repository (on github), this has made it possible for anyone to suggest improvement to the text.
The specification is filled with UML diagrams. I believe the original diagrams were modelled using Sparx Systems Enterprise Architect, and exported as EMF files for import into docx. This approach make it very hard to track changes using a version control system. To improve the situation I have been looking for a good text based UML format with associated command line free software tools on Linux and Windows, to allow anyone to send in corrections to the UML diagrams in the specification. The tool must be text based to work with git, and command line to be able to run it automatically to generate the diagram images. Finally, it must be free software to allow anyone, even those that can not accept a non-free software license, to contribute.
I did not know much about free software UML modelling tools when I started. I have used dia and inkscape for simple modelling in the past, but neither are available on Windows, as far as I could tell. I came across a nice list of text mode uml tools, and tested out a few of the tools listed there. The PlantUML tool seemed most promising. After verifying that the packages is available in Debian and found its Java source under a GPL license on github, I set out to test if it could represent the diagrams we needed, ie the ones currently in the Noark 5 Tjenestegrensesnitt specification. I am happy to report that it could represent them, even thought it have a few warts here and there.
After a few days of modelling I completed the task this weekend. A temporary link to the complete set of diagrams (original and from PlantUML) is available in the github issue discussing the need for a text based UML format, but please note I lack a sensible tool to convert EMF files to PNGs, so the "original" rendering is not as good as the original was in the publised PDF.
Here is an example UML diagram, showing the core classes for keeping metadata about archived documents:
@startuml skinparam classAttributeIconSize 0 !include media/uml-class-arkivskaper.iuml !include media/uml-class-arkiv.iuml !include media/uml-class-klassifikasjonssystem.iuml !include media/uml-class-klasse.iuml !include media/uml-class-arkivdel.iuml !include media/uml-class-mappe.iuml !include media/uml-class-merknad.iuml !include media/uml-class-registrering.iuml !include media/uml-class-basisregistrering.iuml !include media/uml-class-dokumentbeskrivelse.iuml !include media/uml-class-dokumentobjekt.iuml !include media/uml-class-konvertering.iuml !include media/uml-datatype-elektronisksignatur.iuml Arkivstruktur.Arkivskaper "+arkivskaper 1..*" <-o "+arkiv 0..*" Arkivstruktur.Arkiv Arkivstruktur.Arkiv o--> "+underarkiv 0..*" Arkivstruktur.Arkiv Arkivstruktur.Arkiv "+arkiv 1" o--> "+arkivdel 0..*" Arkivstruktur.Arkivdel Arkivstruktur.Klassifikasjonssystem "+klassifikasjonssystem [0..1]" <--o "+arkivdel 1..*" Arkivstruktur.Arkivdel Arkivstruktur.Klassifikasjonssystem "+klassifikasjonssystem [0..1]" o--> "+klasse 0..*" Arkivstruktur.Klasse Arkivstruktur.Arkivdel "+arkivdel 0..1" o--> "+mappe 0..*" Arkivstruktur.Mappe Arkivstruktur.Arkivdel "+arkivdel 0..1" o--> "+registrering 0..*" Arkivstruktur.Registrering Arkivstruktur.Klasse "+klasse 0..1" o--> "+mappe 0..*" Arkivstruktur.Mappe Arkivstruktur.Klasse "+klasse 0..1" o--> "+registrering 0..*" Arkivstruktur.Registrering Arkivstruktur.Mappe --> "+undermappe 0..*" Arkivstruktur.Mappe Arkivstruktur.Mappe "+mappe 0..1" o--> "+registrering 0..*" Arkivstruktur.Registrering Arkivstruktur.Merknad "+merknad 0..*" <--* Arkivstruktur.Mappe Arkivstruktur.Merknad "+merknad 0..*" <--* Arkivstruktur.Dokumentbeskrivelse Arkivstruktur.Basisregistrering -|> Arkivstruktur.Registrering Arkivstruktur.Merknad "+merknad 0..*" <--* Arkivstruktur.Basisregistrering Arkivstruktur.Registrering "+registrering 1..*" o--> "+dokumentbeskrivelse 0..*" Arkivstruktur.Dokumentbeskrivelse Arkivstruktur.Dokumentbeskrivelse "+dokumentbeskrivelse 1" o-> "+dokumentobjekt 0..*" Arkivstruktur.Dokumentobjekt Arkivstruktur.Dokumentobjekt *-> "+konvertering 0..*" Arkivstruktur.Konvertering Arkivstruktur.ElektroniskSignatur -[hidden]-> Arkivstruktur.Dokumentobjekt @enduml
The format is quite compact, with little redundant information. The text expresses entities and relations, and there is little layout related fluff. One can reuse content by using include files, allowing for consistent naming across several diagrams. The include files can be standalone PlantUML too. Here is the content of media/uml-class-arkivskaper.iuml:
@startuml class Arkivstruktur.Arkivskaper{ +arkivskaperID : string +arkivskaperNavn : string +beskrivelse : string [0..1] } @enduml
This is what the complete diagram for the PlantUML notation above look like:
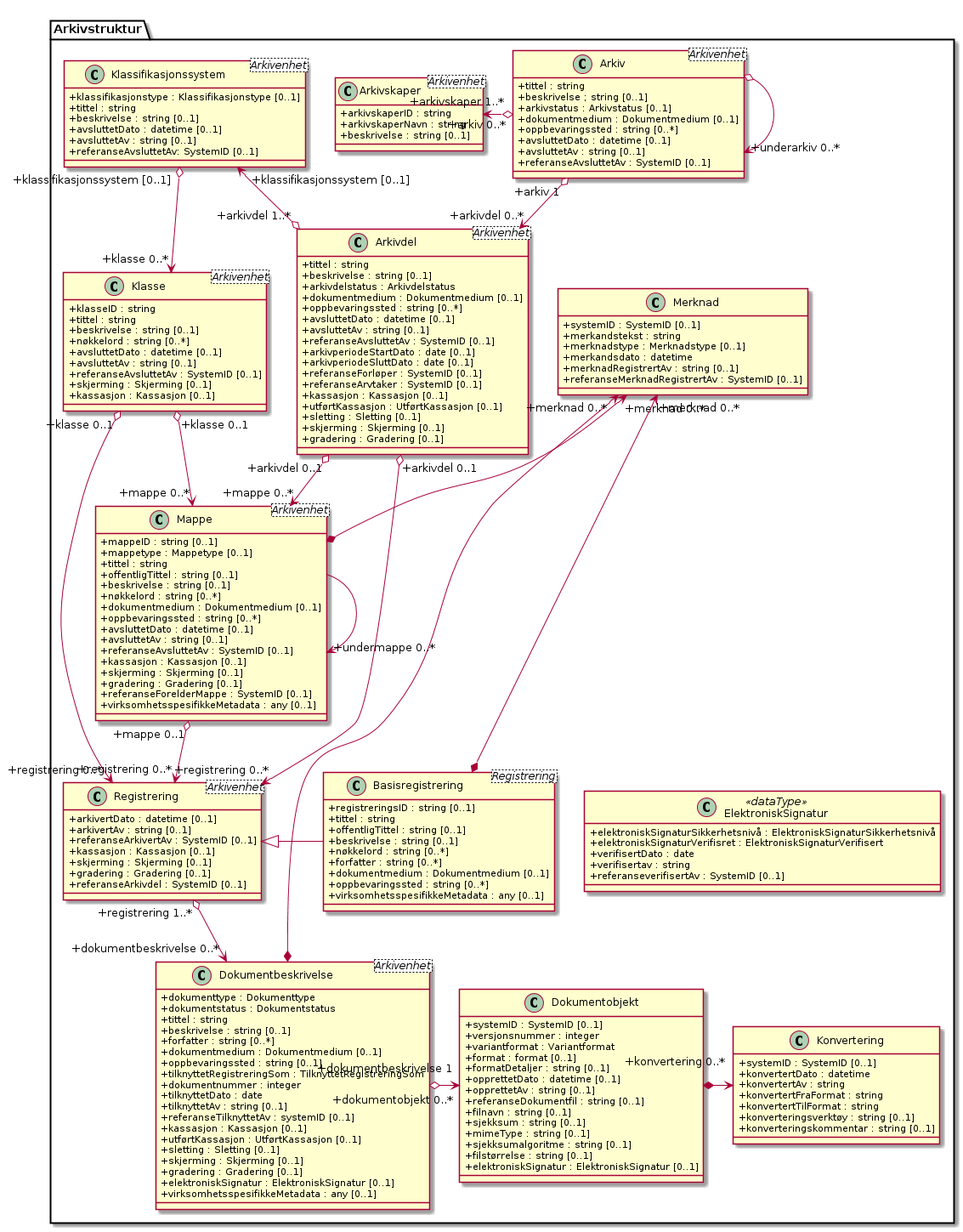
A cool feature of PlantUML is that the generated PNG files include the entire original source diagram as text. The source (with include statements expanded) can be extracted using for example exiftool. Another cool feature is that parts of the entities can be hidden after inclusion. This allow to use include files with all attributes listed, even for UML diagrams that should not list any attributes.
The diagram also show some of the warts. Some times the layout engine place text labels on top of each other, and some times it place the class boxes too close to each other, not leaving room for the labels on the relationship arrows. The former can be worked around by placing extra newlines in the labes (ie "\n"). I did not do it here to be able to demonstrate the issue. I have not found a good way around the latter, so I normally try to reduce the problem by changing from vertical to horizontal links to improve the layout.
All in all, I am quite happy with PlantUML, and very impressed with how quickly its lead developer responds to questions. So far I got an answer to my questions in a few hours when I send an email. I definitely recommend looking at PlantUML if you need to make UML diagrams. Note, PlantUML can draw a lot more than class relations. Check out the documention for a complete list. :)
As usual, if you use Bitcoin and want to show your support of my activities, please send Bitcoin donations to my address 15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.